
Throughout 2023, S-RM helped some of the world’s largest companies recover from ransomware attacks without paying a ransom. Along the way, we learnt some valuable lessons which have shaped how we approach recovery. In this article, James Jackson and Tim Geschwindt share insights and four key lessons from the field.
This article is the fifth in a special series on cyber incident response which will culminate in the S-RM IR Bulletin later this month. Missed the last instalment? Read How to shoot a silver bullet: avoiding common pitfalls cyber Endpoint Detection and Response deployments now.
A prickly situation
In late November 2023, S-RM was brought into a case affecting a large manufacturer and supplier for major construction projects worldwide. During the first scoping call with the client and their insurers, it became clear this was a significant incident. A ransomware group known as Cactus had brought down the entire global network, encrypting physical servers at each manufacturing site and office in 32 countries. The IT team consisted of 11 people, servicing more than 3,000 employees around the world. They immediately flagged they did not have enough resources.
This posed a severe challenge: it quickly became clear that recovering the manufacture’s production facilities would only be possible by going on site at each and every location to physically access and recover the affected on premise assets. The client could not do this on their own and their staff had no experience of running through rapid recovery response processes. Each passing hour was costing the business more than EUR 45,000 in lost revenue. There was no time to lose.
For manufacturers, each hour of downtime can cause extensive financial damage. The recovery strategy must therefore prioritise speed and a pragmatic approach to security above all else.
Perfection in containment must sometimes be sacrificed in favour of effective risk management and emergency enhanced monitoring. Equally, forensic investigation teams might need to be circumspect about what they ask for the first 48 hours and prioritise simple evidence preservation at first.
At S-RM, to balance these priorities, we use our Secure Rapid Recovery ('SRR') incident response model. This recovery framework means we waste little time deciding what to do and can focus on the how we do it as quickly as possible.
Secure Rapid Recovery (‘SRR’)
Within five hours of the first call, we had a team at two locations in the UK and Germany which hosted the core IT functions of the global network. Within 14 hours we had teams arriving at two locations in South America, three locations in North America, one in Asia-Pacific, and at four locations in Europe. All the teams had the same remit: get access to the affected devices and implement our SRR workflow:
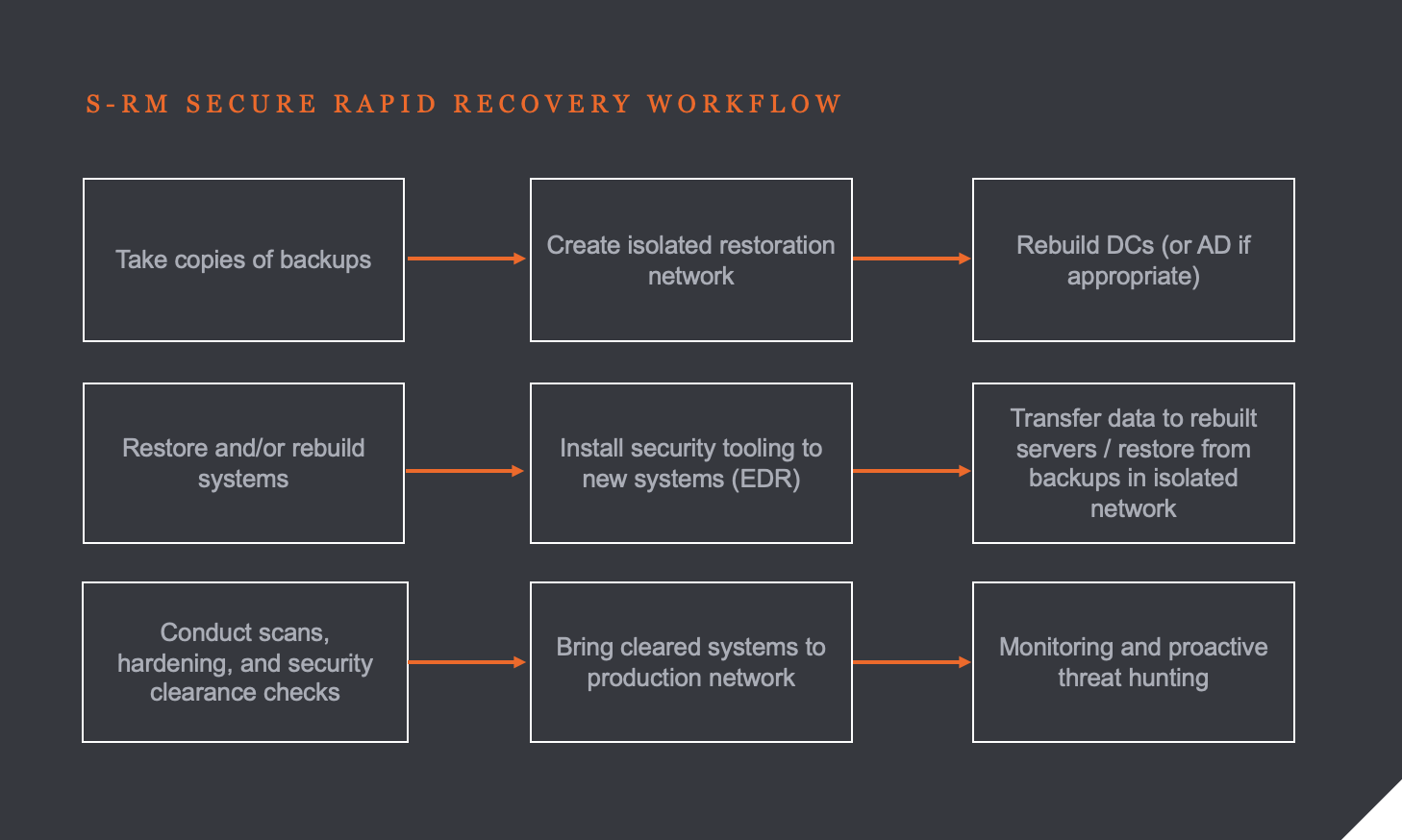
While our on-site teams sprinted through the initial 24 hours, we believed most of the response could be – and should be – delivered remotely to save costs and because it is usually the quickest way of working. Our onsite team worked quickly to restore secure remote access that our global team could use to weigh in. This turbo-charged the response as we lent more hands to the pump.
By day four of the response, our client’s IT team was backed up by an S-RM team of more than 43 responders across 11 countries. We were also able to enlist 33 of the client’s staff supporting in various ways – from reimaging laptops to driving four hours across a US state to give one of our responders a key to a server room. Within 72 hours, which fortunately coincided with a weekend, the core functions of the IT network were online, and within 96 hours, the business was operating at approximately 90 percent of their original capacity.
Learning our lessons
Not all recovery work goes as smoothly as in this case. Over the last four years as we have built and refined our Recovery and Restoration service, we have learnt lessons – sometimes the hard way – about how to tackle a complex recovery project from a strategic, tactical and operational level. Although we cannot distil all of these learnings here, four resonate across our cases.
1. Get it right from day 1
The first 24-48 hours are absolutely critical for any incident response, but they are even more so when the response involves a significant recovery and restoration workstream. When a ship disembarks from Portsmouth and sets its course for New York, if the trajectory is off by just a single degree, the ship would likely make landfall approximately 85 kilometres off course.
In the same way, many mistakes made on day one can have a severe impact later on, such as starting the recovery before agreeing on the security strategy meaning work must be redone; wiping machines without evidence collection resulting in a lack of understanding of what the perpetrator did; shutting down machines when they are mid encryption resulting in permanent data loss; or, contacting the threat actor without using expert negotiators; among others.
Most have a simple solution, which is closely linked to our second learning.
2. Communicate, collaborate
The best recovery projects involve a high degree of communication and collaboration. It is not a simple feat: We are asking a large group of people who have never worked together before to create a seamless team that is well organised, understanding their roles and responsibilities, and works together with each other team to meet our joint objectives.
To accomplish this, the response team across different regions, time zones, specialisms, organisations, and mandates has to find a way to collaborate efficiently and communicate effectively. We find that morning meetings in sub-teams focused on specific objectives, and then a wider Crisis Management Team (‘CMT’) meeting in the afternoon comprising of the leader from each sub-team works well to ensure meetings are efficient and all teams are kept in the loop. Outside of these meetings, we advocate for continuous comms through channels like Microsoft Teams or WhatsApp, depending on the client requirements.
Nonetheless, it is a challenge we find many of our clients struggle with. In very few professional contexts are employees expected to function in the way they need to in a recovery response scenario, particularly when many key employees – often employees in IT, technology, compliance and at C-suite level – are under the significant pressure to rescue the business.
3. Sustainability
The pressure is an underappreciated impact of ransomware and other cybercrime: the damage done to the people who have to respond and react. Over the last few years we have seen clients’ staff – particularly those in IT – experience burnout, fatigue, psychological breakdowns, severe stress. The ramifications of this on their personal and professional lives, both short term and long term can be significant. This can also be exacerbated by threat actors who harass victims, calling them on their home and personal numbers, demanding they tell their bosses to pay a ransom. The overall experience is stressful, often lasts for weeks, and frequently frays the nerves people not used to this type of work.
To counter this, when we are leading a client’s recovery, we build sustainability in at the right times, ensuring that the right people at the client (and our own teams) are rotated, get rest and are able sustain their efforts across the whole recovery, without jeopardising their wellbeing. Working this way is also not just about protecting people. Burnt out and stressed staff are more likely to make mistakes which risk the integrity of the entire recovered network. Relying and leaning on S-RM to ease these burdens is just one of the reasons why we are brought in to support.
4. Be proportionate
The last lesson is proportionality. There is a careful balance to be struck between cutting corners to achieve an early recovery, and painstakingly going to the nth degree to ensure each device is 100% clean before use. To accomplish the latter, traditional recovery projects used to involve deep-dive forensics of every recovered system to clear them for use in the production network, triggering long delays in the recovery and exorbitant forensics costs.
At S-RM, we have adopted a process known as ‘Sheep Dipping’, which balances the need to ensure the recovered network is secure and the risk of reinfection is low, while also ensuring business interruption is minimised. In this process, we help our clients recover their assets from the earliest viable backups – which may be untrusted or infected – we then install tools to give visibility of, and access to, the device, and finally run a semi-automated review to identify and eradicate malware, persistence and other malicious artefacts, effectively ‘cleaning’ the devices. Each one of the devices is pushed through this pipeline and we take pragmatic, risk-based decisions with our clients about those they may need to be rebuilt from scratch, decommissioned or recovered from an earlier backup. With this method, we manage risks of re-attack while avoiding costly and disproportionate blanket rebuild approaches.
Frameworks work
Cyber recovery and restoration work has to adapt and evolve as new technologies, both proactive and reactive change how we approach recovery. One size does not fit all, when each client is completely different, but our recovery projects have demonstrated our Secure Rapid Recovery framework is effective. Applied with the right flexibility, this framework ensures there is a clear strategy agreed on day one, effective channels of communication, a sustainable battle plan, all the while maintaining a proportional approach to mitigate the risks.



